
What Can You Do with A Web Crawler?: A 2021 report estimates that global internet traffic for 2022 will exceed all traffic generated prior to 2017. Such is the scale at which the digital space has grown over just five years. This growth is a result of the digitization of shopping, work, service delivery, human interactions, and more. With it, scores of data from users of these digitized platforms are generated every second.
Notably, companies can utilize this data in many ways to stay ahead of their competition. For instance, ethically acquired data can help improve decision-making, enhance marketing campaigns, increase sales, grow the customer base through lead generation, and more. But given that this data exists in large volumes, there is a need to collect it efficiently and within a short time. This is where web crawling, conducted by a web crawler, comes in! So, what is a web crawler?
Table of Contents
What is a web crawler?
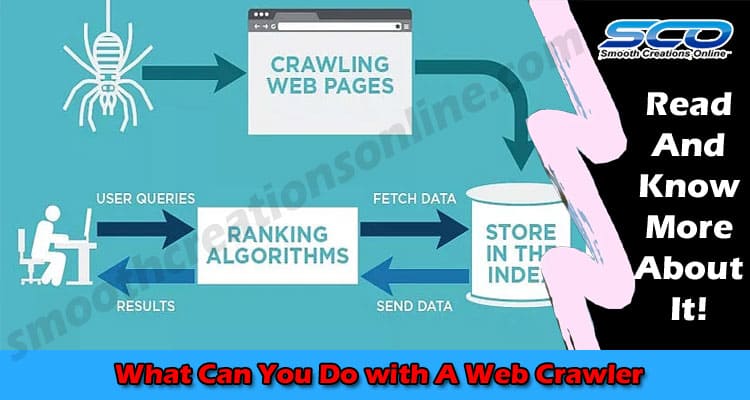
A web crawler or spider is a bot that automatically scours through websites to collect the data stored in web pages as well as follow links therein to discover new pages. The collected data is organized and subsequently stored in databases known as indexes. Importantly, by undertaking these different steps, spiders carry out web crawling. And there are many ways in which businesses can use spiders. Navigate here to learn more about the topic.
Uses of web crawling
Web crawling is employed in myriad applications. These include:
- Search engine indexing
- Web page and content discovery by aggregator sites
- Search engine optimization (SEO)
- Collecting competitive information such as pricing and emerging trends
- Web scraping
- Web analysis
It is worth pointing out that businesses use web crawling either directly or indirectly, as we have detailed below.
Search engine indexing
Search engine indexing is the process by which search engines directly use web crawlers to discover new web pages. The spiders then go through the data, collect key information, and archive the web pages in indexes.
When a user types a phrase on the search bar, the search engine retrieves the relevant web pages from the index and presents them as hierarchical links. It is worth pointing out that the relevance of the web pages is partly based on keywords collected by spiders.
Content discovery by aggregator sites
Aggregator sites discover websites that contain related information through web crawling. These websites then combine the data from disparate sources into a single resource. This enhances convenience by ensuring users only visit a single site that contains all the information needed instead of multiple sites that have fragmented data.
Notably, there are different types of aggregator sites, each of which serves a unique function. For instance, news aggregators combine newly uploaded news items while social aggregators collect data from social media platforms and conflate them in a single location.
Search engine optimization
Search engine optimization (SEO) is the practice by which websites improve their ranking on search engine results pages (SERPs). Websites achieve a high ranking by integrating several vital elements, including keywords.
As we have established earlier, search engine bots collect and store words. They also associate web pages’ relevance with the frequency with which some keywords have been used. Usually, SEO service providers extract relevant keywords from SERPs that they then recommend to web copywriters to include in their web content. By integrating these keywords as well as other recommendations, websites can rank high on search engines.
But first, the website should fundamentally allow search engine crawlers to index the pages therein for it to rank on search engines in the first place. Thus, the success of SEO initiatives depends on several related factors.
Competitive information
The digitization of various processes has domiciled information in one location: the internet. Companies that use some of this information appropriately and strategically can gain a competitive advantage over their peers. Examples of data that offer this result include pricing information, new emerging trends, customer feedback, the number of competitors in a market, and more.
Businesses can get ahold of this data by either undertaking web scraping or using aggregator sites. The latter approach is more convenient and requires fewer resources. It offers competitive data from news, social, and shopping aggregators.
Web scraping
Also known as web data collection or web data harvesting, web scraping is the automated gathering of data from websites using programs known as scrapers. Web scraping relies on web crawling as the latter helps scrapers discover new web pages from which data can be extracted.
Web analysis
At the core of web crawlers’ operations is their ability to follow hyperlinks. Thus, web analysis tools use spiders to collect data on outbound, inbound, and internal links. You can establish which sites have linked their pages to your websites.
Conclusion
While this article has only discussed six ways in which you can use web crawling to satisfy your business’s or individual needs, there are endless possibilities. This means that you can come up with a unique use case for web crawlers, one that can give you an unprecedented competitive advantage.
Also Read – What Are Some Advantages of Using WordPress?